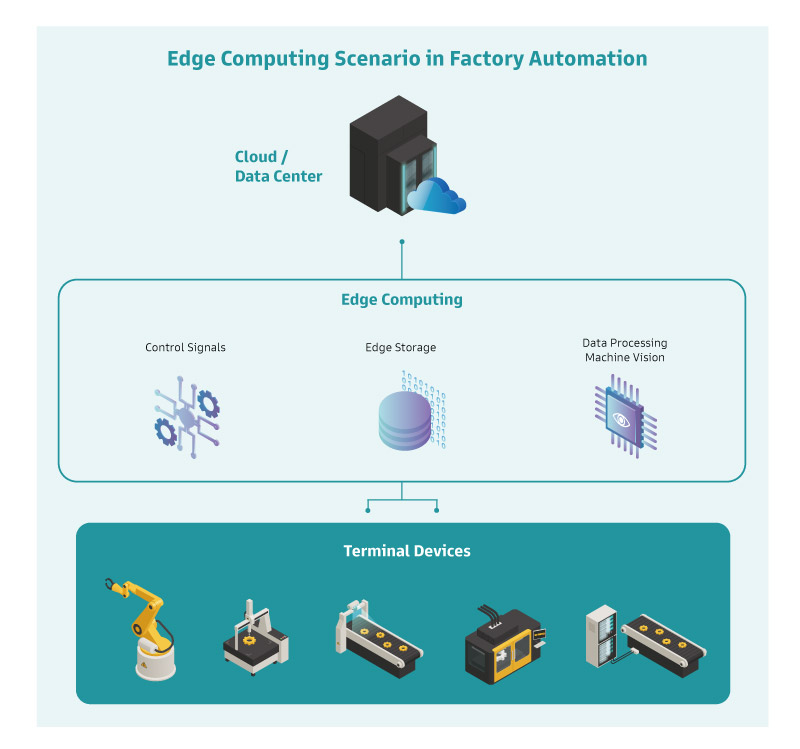
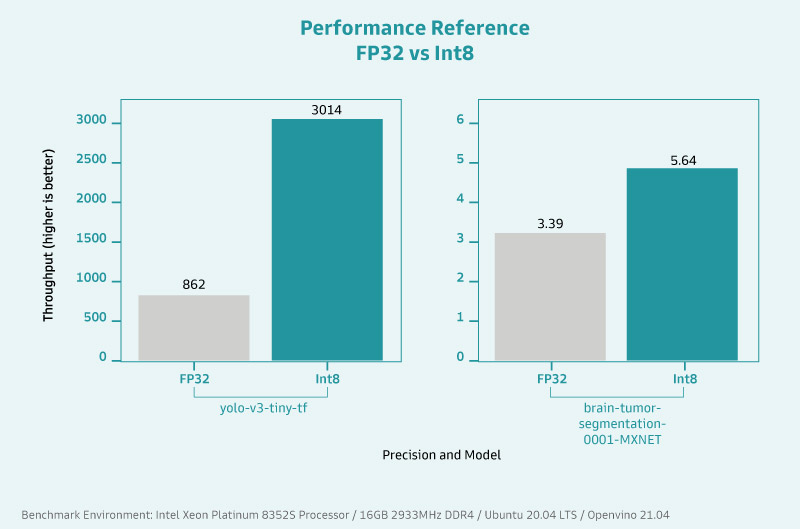
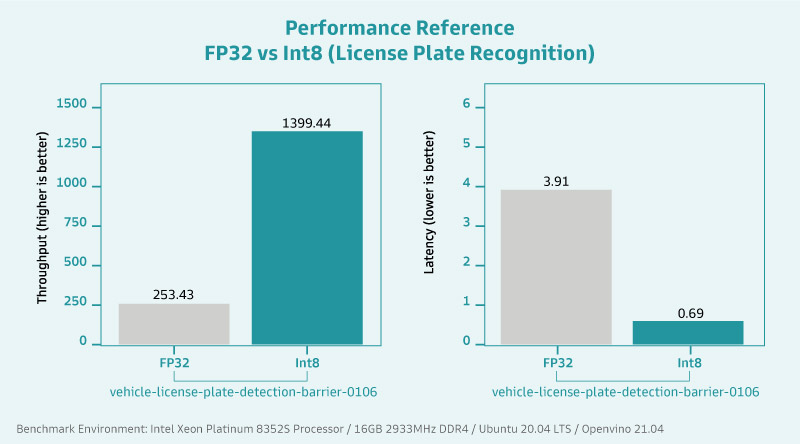
邊緣運算的明顯優勢
在工(gōng)業及醫(yī)療産(chǎn)業,機器視覺乃工(gōng)業4.0 之母,亦是維持××生産(chǎn)力的重要環節。身為(wèi)人工(gōng)智能(néng)×常扮演的應用(yòng)面向,負責機器視覺的運算裝(zhuāng)置在效能(néng)的要求上尤其吃重,它需要無遲滞的接收來自終端設備傳來的影像數據,快速而準确的分(fēn)析後做出回應,并同時儲存結果及記錄對應的影像,對裝(zhuāng)置的對外帶寬及運算核心能(néng)耐是一大考驗。
而在邊緣運算的框架下,這些數據必須盡其可(kě)能(néng)的在終端實時處理(lǐ)及分(fēn)析,不宜再全數回傳至雲端進行,使軟件、硬件及數據數據皆得以×接近邊緣的方式運作(zuò)。此舉除了可(kě)以減少傳輸帶寬,也能(néng)避免因為(wèi)數據延遲拖累生産(chǎn)效率,用(yòng)×快的反應速度來實時與設備溝通。
邊緣運算要運算哪些内容?影像、聲音、以及來自各種裝(zhuāng)置的感測數據。在講求生産(chǎn)效率的産(chǎn)線(xiàn)以及精(jīng)準度的醫(yī)療應用(yòng),這些内容必需極其精(jīng)細,才有(yǒu)可(kě)能(néng)産(chǎn)生準确的結果,精(jīng)細的内容則意味着龐大的數據量需要處理(lǐ)。
一言以敝之,隻靠雲端架構難以應付終端的運算需求,在終端布署大量而繁雜的運算設備又(yòu)會對空間及維護成本上造成難題。邊緣運算服務(wù)器于是順理(lǐ)成章的擔當此重任,在×接近數據的地方接收數據、處理(lǐ)數據、回傳數據,可(kě)謂身兼數職。在整個應用(yòng)場域裏,我們可(kě)以把它當做是×靠近終端裝(zhuāng)置的節點,在接口的整合能(néng)力、軟件的彈性支持及虛拟化能(néng)力也會是重要考慮,這次我們先把焦點放在「效能(néng)」。